IBM: Operations Analytics
Getting ahead of data center failures before they become outages.
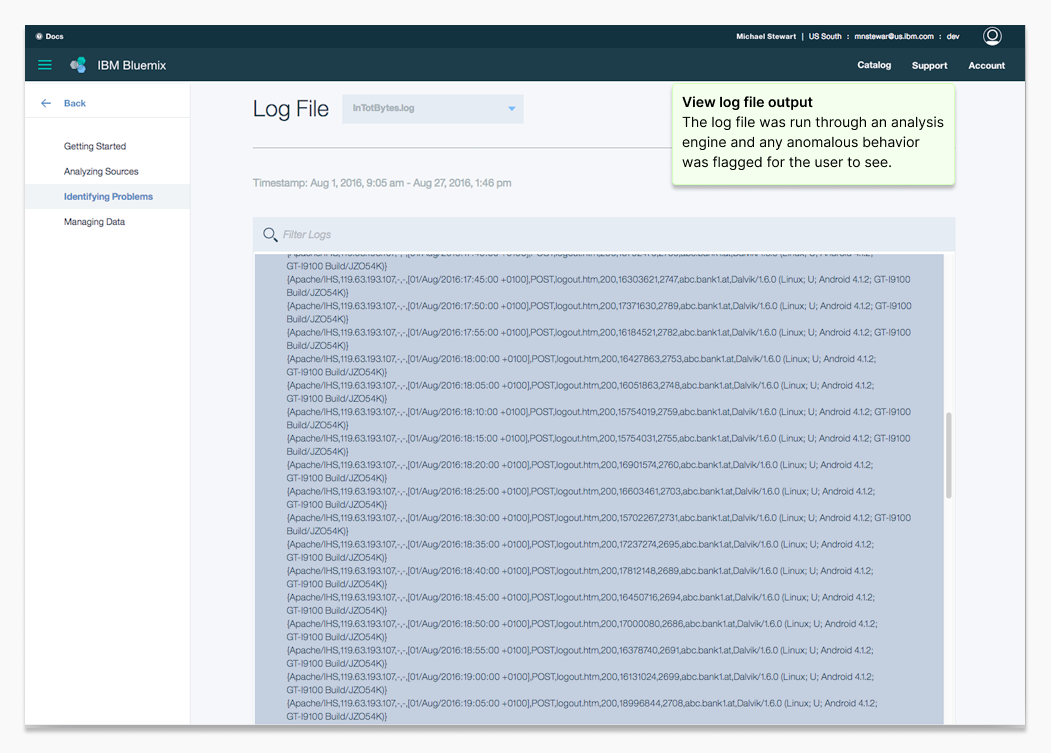
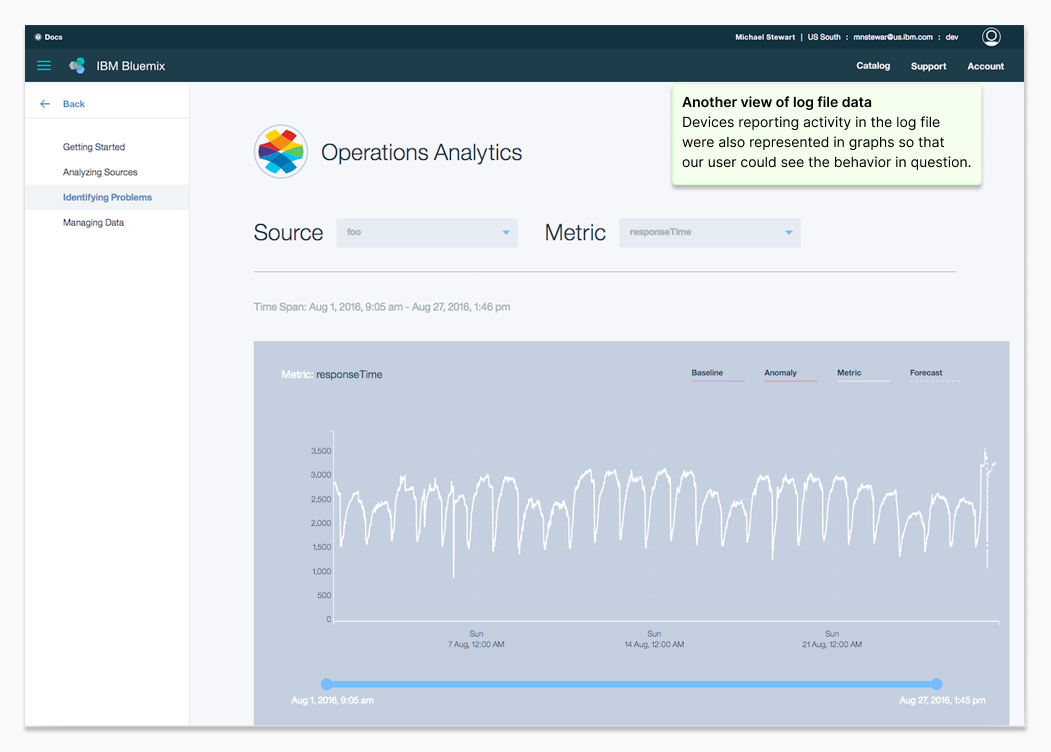
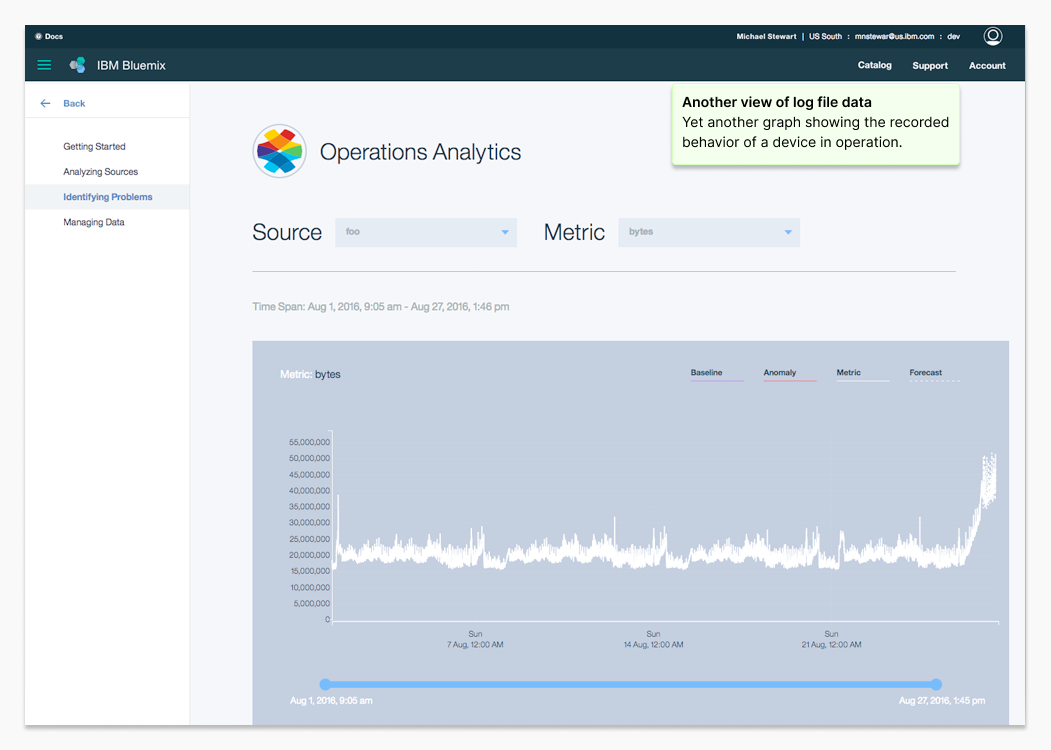
Operations Analytics helped system administrators detect abnormal behavior in data center logs early enough to prevent outages. Users uploaded log files and used the tool to spot patterns that pointed to failing hardware or performance bottlenecks.
Our primary user was Rich, a system administrator tasked with maintaining seamless operations across the infrastructure.
As Design Lead, I focused on team execution and decision-making, keeping design aligned with sprint delivery and user validation:
- Backlog Management: Partnering with the Offering Manager and Development team to refine and prioritize user stories
- Sprint Planning and Delivery: Ensuring designs were assigned to the team, completed within the two-week sprint cycle, and delivered on schedule
- User Validation: Working closely with our user researcher to validate designs with real users and incorporating their feedback into iterative improvements
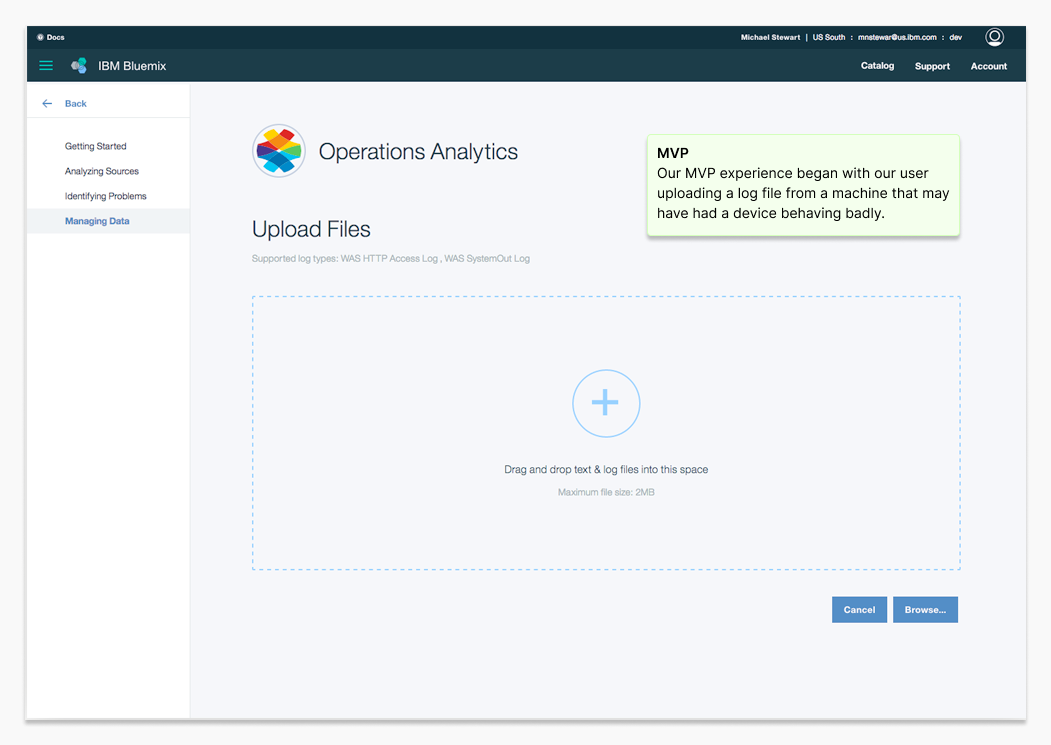
An MVP of the product was successfully launched on the IBM Bluemix cloud catalog, providing IT professionals like Rich the tools to safeguard their systems and prevent potential failures.

After conducting user interviews, we built empathy maps from which we extracted user insights.
"It's the little issues that go un-detected that really come back to bite you."
— Interview subject
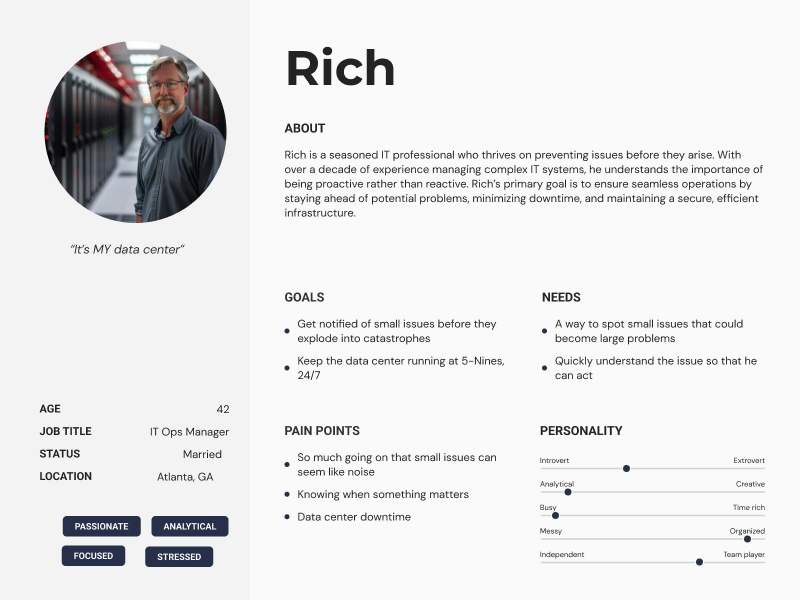
Once we had clear insights and a good understanding of our target user, we created a simple proto-persona. We kept it simple and treated it for what it's good for: a shared reference that kept the team talking about the same person instead of drifting toward edge cases and hypotheticals.
"I've got so much going on, if you can help even a little in staying ahead, that would be huge."
— Interview subject

This is an initial as-is flow diagram done for Operations Analytics. We began by looking at a typical data center tech's course of action during their workday. This particular scenario revealed the following points:
- Surface severity and confidence together. The tech could see that something was wrong but not how wrong. The product needed to communicate not just the anomaly, but a signal about its likely trajectory and outcome.
- Consolidate cross-device context into a single view. The multi-application and -dashboard problem was a direct consequence of siloed monitoring and reporting. Bringing related signals together was a systems-level fix, not a UI polish.
- Reduce the cost of the judgment call. If the tech had clearer insights, the "act or wait" decision becomes lower-stakes and faster. The design goal wasn't just to surface information earlier, but to make the right action feel obvious.
"Keeping the data center running is Job One."
— Interview subject

We did a to-be flow for our offering MVP. We knew that the MVP would be less than ideal but would get the tech working in a slightly different way. The MVP to-be scenario pointed to the following:
- Deliver clarity at the moment of highest uncertainty. The MVP didn't change how the tech noticed a problem, but it changed what happened next. Uploading a log file and getting ranked, component-level insight replaced the most costly part of the as-is: guessing where to look.
- Ground the action decision in evidence, not experience. In the as-is, the call to act or wait was made on instinct. The MVP gave the tech the details needed to make that same call with confidence.
- Respect the existing workflow while improving it. The tech still starts from familiar territory: lights, alerts, a log file. The MVP meets them there rather than asking them to change everything at once.
- Set up the complete offering without overpromising it. The MVP ends the same way the complete offering does, with the tech returning to a monitoring stance. The habit was being established even before the full product existed.

We also mapped the offering in its mature state, confident it would fundamentally change how techs like Rich approached their work. The complete offering scenario pointed to four design priorities:
- Shift from reactive to continuous monitoring. The complete offering was designed around a persistent agent installed across the data center, so the tech was always watching rather than responding after the fact.
- Replace experience-based triage with ranked, actionable signals. Rather than relying on the tech's instinct to assess criticality, the product surfaces a prioritized action list so judgment is applied to decisions, not sorting.
- Reduce the cost of knowing what to do next. By step three of the mature flow, the tech has a working plan. The goal was to collapse the gap between "something is wrong" and "here is what I do about it."
- Close the loop after intervention. The flow ends with the tech back at the dashboard. The design treated monitoring as an ongoing posture — at one "pane of glass" — rather than a task to complete across multiple systems.
Key decisions
Outcomes
- Time to detect — Ops teams were reactive and anomalies surfaced after escalation to incidents. Log analysis made pattern recognition faster and directly actionable. Confirmed through as-is vs to-be scenario flows validated with target users.
- Proactive interventions — Monitoring was reactive and intervention came after impact. MVP gave administrators a reason to investigate early signals before failures. Confirmed through quote synthesis, scenario validation sessions, and launch stakeholder feedback.
- Design-to-delivery reliability — Delivery pressure in a complex domain risked unvalidated UX decisions reaching engineering. Sprint-aligned design and validation rhythm established across the workstream. Evidenced by backlog refinement cadence with the offering manager plus researcher-supported validation.
- Monitoring signals were made actionable, reducing ambiguity at the "what do I do next" moment
- The investigation and intervention path was clarified so administrators could act on early signals
User interviews and empathy mapping established the as-is workflow. Scenario validation sessions confirmed the to-be model. The MVP launched on IBM Bluemix and later evolved into a key IBM Z-series monitoring tool.
Operations Analytics MVP product screens. This humble application MVP went on to become a key IBM Z-series server monitoring tool.
{kind=link}
{kind=link}
{kind=link}
{kind=link}